

subagents parameter 中指定 custom subagents。Subagents 适用于 context quarantine(保持 main agent 的 context clean),也适用于提供 specialized instructions。
本页介绍 synchronous subagents,即 supervisor 会 block,直到 subagent 完成。对于 long-running tasks、parallel workstreams,或需要 mid-flight steering 和 cancellation 的场景,请参阅 Async subagents。
Why use subagents?
Subagents 解决 context bloat problem。当 agents 使用具有 large outputs 的 tools(web search、file reads、database queries)时,context window 会很快被 intermediate results 填满。Subagents 会隔离这些 detailed work,main agent 只接收 final result,而不是生成该结果的 dozens of tool calls。 何时使用 subagents:- ✅ 会 clutter main agent context 的 multi-step tasks
- ✅ 需要 custom instructions 或 tools 的 specialized domains
- ✅ 需要 different model capabilities 的 tasks
- ✅ 希望 main agent 专注于 high-level coordination 时
- ❌ Simple、single-step tasks
- ❌ 需要 maintain intermediate context 时
- ❌ Overhead 超过 benefits 时
Configuration
subagents 应是 dictionaries 或 CompiledSubAgent objects 的 list。有两种类型:
Default subagent
除非你已经提供同名 synchronous subagent,否则 Deep Agents 会自动添加 synchronousgeneral-purpose subagent。
general-purpose subagent 默认具有 filesystem tools,并且可以用 additional tools/middleware 自定义。
- 若要替换它,请传入你自己的名为
general-purpose的 subagent。 - 若要 rename 或 re-prompt auto-added version,请在 active harness profile 上设置
general_purpose_subagent=GeneralPurposeSubagentProfile(...)。 - 若要 disable 它,请参阅下面的 Running without subagents。
Running without subagents
若要运行不带task tool 的 agent,请执行两件事:
- 在 active harness profile 上设置
general_purpose_subagent=GeneralPurposeSubagentProfile(enabled=False)。 - 不要在
create_deep_agent上通过subagents=传入 synchronous subagents。
SubAgentMiddleware(以及 task tool)。如果没有默认 subagent,也没有 caller-provided subagent,agent 会在没有 delegation 的情况下运行。
Async subagents 不受影响,它们通过自己的 middleware 和 tools 流转,详见 Async subagents。
Custom subagents
你可以使用subagents parameter 定义带 specific tools 的 specialized subagents。例如作为 code reviewer、web researcher 或 test runner。
对于多数 use cases,请使用 SubAgent dictionaries 将 subagents 定义为 dictionaries。对于 complex workflows,请使用 CompiledSubAgent:
SubAgent (Dictionary-based)
将 subagents 定义为匹配SubAgent spec 的 dictionaries,包含以下 fields:
| Field | Type | Description |
|---|---|---|
name | str | Required。Subagent 的 unique identifier。Main agent 调用 task() tool 时使用此 name。Subagent name 会成为 AIMessages 和 streaming 的 metadata,有助于区分 agents。 |
description | str | Required。描述此 subagent 做什么。应具体且 action-oriented。Main agent 使用它决定何时 delegate。 |
system_prompt | str | Required。Subagent 的 instructions。Custom subagents 必须定义自己的 instructions。包含 tool usage guidance 和 output format requirements。 不从 main agent 继承。 |
tools | list[Callable] | Optional。Subagent 可使用的 tools。保持 minimal,只包含所需内容。 默认从 main agent 继承。指定时会完全 override inherited tools。 |
model | str | BaseChatModel | Optional。Override main agent 的 model。省略时使用 main agent 的 model。 默认从 main agent 继承。你可以传入 model identifier string,例如 'openai:gpt-5.4'(使用 'provider:model' format),或 LangChain chat model object(await initChatModel("gpt-5.4") 或 new ChatOpenAI({ model: "gpt-5.4" }))。 |
name | string | Required。Subagent 的 unique identifier。Main agent 调用 task() tool 时使用此 name。Subagent name 会成为 AIMessages 和 streaming 的 metadata,有助于区分 agents。 |
description | string | Required。描述此 subagent 做什么。应具体且 action-oriented。Main agent 使用它决定何时 delegate。 |
systemPrompt | string | Required。Subagent 的 instructions。Custom subagents 必须定义自己的 instructions。包含 tool usage guidance 和 output format requirements。 不从 main agent 继承。 |
tools | StructuredTool[] | Optional。Subagent 可使用的 tools。保持 minimal,只包含所需内容。 默认从 main agent 继承。指定时会完全 override inherited tools。 |
model | LanguageModelLike | string | Optional。Override main agent 的 model。省略时使用 main agent 的 model。 默认从 main agent 继承。你可以传入 model identifier string,例如 'openai:gpt-5.4'(使用 'provider:model' format),或 LangChain chat model object(await initChatModel("gpt-5.4") 或 new ChatOpenAI({ model: "gpt-5.4" }))。 |
middleware | AgentMiddleware[] | Optional。用于 custom behavior、logging 或 rate limiting 的 additional middleware。 不从 main agent 继承。 |
interruptOn | Record<string, boolean | InterruptOnConfig> | Optional。为 specific tools 配置 human-in-the-loop。Options:True、False,或带 allowed_decisions 的 InterruptOnConfig。需要 checkpointer。默认从 main agent 继承。Subagent value 会 override default。 |
skills | string[] | Optional。Skills source paths。指定后,subagent 会从这些 directories 加载 skills(例如 ["/skills/research/", "/skills/web-search/"])。这让 subagents 可以拥有不同于 main agent 的 skill sets。不从 main agent 继承。只有 general-purpose subagent 会继承 main agent 的 skills。当 subagent 有 skills 时,它会运行自己的 independent SkillsMiddleware instance。Skill state 是 fully isolated:subagent loaded skills 对 parent 不可见,反之亦然。 |
responseFormat | ResponseFormat | Optional。Subagent 的 Structured output schema。设置后,parent 会接收 subagent result 的 JSON,而不是 free-form text。接受 Zod schemas、JSON schema objects、toolStrategy(...) 或 providerStrategy(...)。请参阅 Structured output。 |
permissions | FilesystemPermission[] | Optional。Subagent 的 Filesystem permission rules。设置后,会完全 replaces parent agent 的 permissions。 默认从 main agent 继承。 |
CompiledSubAgent
对于 complex workflows,请将 prebuilt LangGraph graph 用作CompiledSubAgent:
| Field | Type | Description |
|---|---|---|
name | str | Required。Subagent 的 unique identifier。Subagent name 会成为 AIMessages 和 streaming 的 metadata,有助于区分 agents。 |
description | str | Required。此 subagent 做什么。 |
runnable | Runnable | Required。Compiled LangGraph graph(必须先调用 .compile())。 |
Using SubAgent
Using CompiledSubAgent
对于更 complex 的 use cases,你可以用CompiledSubAgent 提供 custom subagents。
你可以使用 LangChain 的 create_agent 创建 custom subagent,或使用 graph API 创建 custom LangGraph graph。
如果你正在创建 custom LangGraph graph,请确保 graph 有一个 名为 "messages" 的 state key:
Streaming
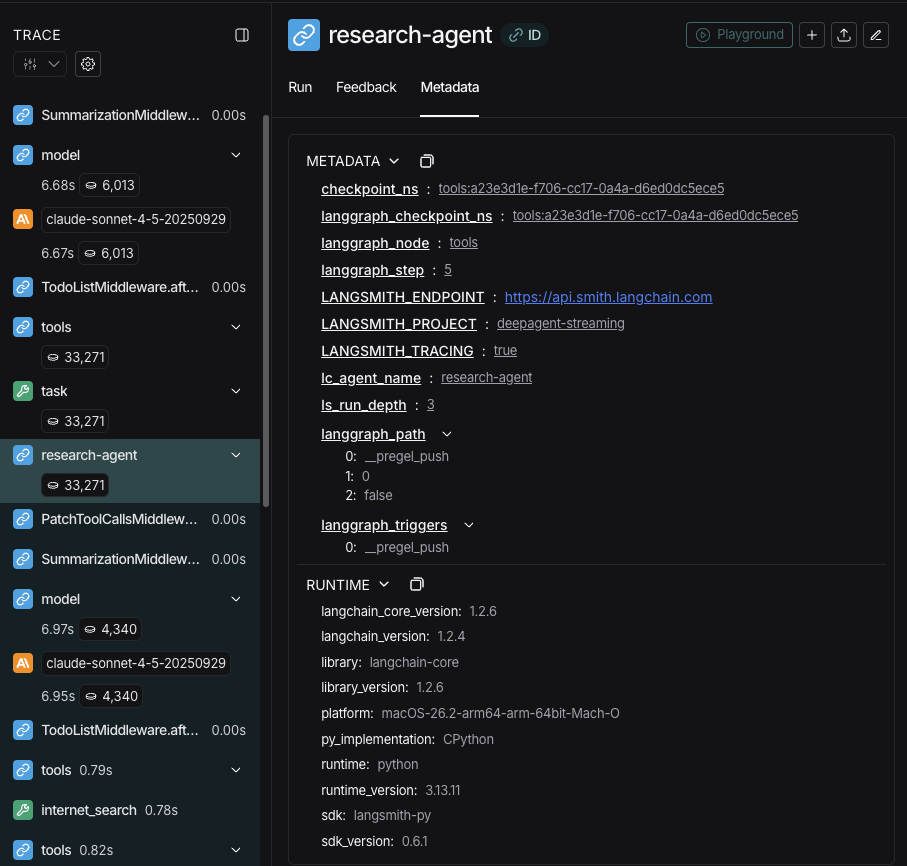
Streaming tracing information 时,agents 的 names 会作为 metadata 中的lc_agent_name 可用。
Review tracing information 时,你可以使用此 metadata 区分 data 来自哪个 agent。
下面的 example 创建一个名为 main-agent 的 deep agent,以及一个名为 research-agent 的 subagent:
"research-agent" 的 subagent 会在任何 associated agent run metadata 中包含 {'lc_agent_name': 'research-agent'}:
Structured output
Subagents 支持 structured output,因此 parent agent 会接收 predictable、parseable JSON,而不是 free-form text。Subagents 的 structured output 需要
deepagents>=1.8.4。responseFormat。Subagent 完成后,其 structured response 会 JSON-serialized,并作为 ToolMessage content 返回给 parent agent。Schema 接受 createAgent 支持的任何内容:Zod schemas、JSON schema objects、toolStrategy(...) 或 providerStrategy(...)。
response_format 时,parent 会按原样接收 subagent 的 last message text。设置后,parent 始终会获得匹配 schema 的 valid JSON,这在 parent 需要 programmatically process result 或将其传给 downstream tools 时很有用。
有关 schema types 和 strategies(tool calling vs. provider-native)的完整 details,请参阅 Structured output。
The general-purpose subagent
除了任何 user-defined subagents,每个 deep agent 始终都可以 access 一个general-purpose subagent。此 subagent:
- 使用自己的 应用 profile overlays 的 default system prompt
- 可以 access 所有相同 tools
- 使用相同 model(除非 overridden)
- 从 main agent 继承 skills(当配置了 skills 时)
Override the general-purpose subagent
在subagents list 中包含 name: "general-purpose" 的 subagent,以替换 default。使用此方式为 general-purpose subagent 配置不同 model、tools 或 system prompt:
enabled flag 设置为 False。
When to use it
General-purpose subagent 很适合在没有 specialized behavior 的情况下进行 context isolation。Main agent 可以将 complex multi-step task 委派给此 subagent,并获得 concise result,而不会受到 intermediate tool calls 的 bloat 影响。Example
Main agent 不需要进行 10 次 web searches 并用 results 填满 context,而是委派给 general-purpose subagent:
task(name="general-purpose", task="Research quantum computing trends")。Subagent 在内部执行所有 searches,并只返回 summary。Skills inheritance
使用create_deep_agent 配置 skills 时:
- General-purpose subagent:自动从 main agent 继承 skills
- Custom subagents:默认不继承 skills,请使用
skillsparameter 给它们自己的 skills
只有配置了 skills 的 subagents 才会获得
SkillsMiddleware instance;没有 skills parameter 的 custom subagents 不会获得。存在该 middleware 时,skill state 在两个方向上都是 fully isolated:parent 的 skills 对 child 不可见,child 的 skills 也不会 propagate 回 parent。Best practices
Write clear descriptions
Main agent 使用 descriptions 决定调用哪个 subagent。请保持具体: ✅ Good:"Analyzes financial data and generates investment insights with confidence scores"
❌ Bad: "Does finance stuff"
Keep system prompts detailed
包含关于如何 use tools 和 format outputs 的具体 guidance:Minimize tool sets
只给 subagents 它们需要的 tools。这会提升 focus 和 security:Choose models by task
不同 models 擅长不同 tasks:Return concise results
指示 subagents 返回 summaries,而不是 raw data:Common patterns
Multiple specialized subagents
为不同 domains 创建 specialized subagents:- Main agent 创建 high-level plan
- 将 data collection 委派给 data-collector
- 将 results 传给 data-analyzer
- 将 insights 发送给 report-writer
- 编译 final output
Context management
当你使用 runtime context invoke parent agent 时,该 context 会自动 propagate 到所有 subagents。每个 subagent run 都会接收你在 parentinvoke / ainvoke call 上传入的相同 runtime context。
这意味着在任何 subagent 内运行的 tools 都可以 access 你提供给 parent 的相同 context values:
Per-subagent context
所有 subagents 都会接收相同 parent context。若要传入特定于某个 subagent 的 configuration,请在 flatcontext mapping 中使用 namespaced keys(用 subagent name 作为 key prefix,例如 researcher:max_depth),或 将这些 settings 建模为 context type 上的 separate fields:
Identifying which subagent called a tool
当 parent 和多个 subagents 共享同一个 tool 时,你可以使用lc_agent_name metadata(与 streaming 中使用的值相同)来判断哪个 agent 发起了 call:
runtime.context 读取 agent-specific settings,并在 branching tool behavior 时从 runtime.config metadata 读取 lc_agent_name。
Troubleshooting
Subagent not being called
Problem:Main agent 试图自己完成工作,而不是 delegating。 Solutions:-
让 descriptions 更具体:
-
指示 main agent delegate:
Context still getting bloated
Problem:虽然使用了 subagents,但 context 仍然被填满。 Solutions:-
指示 subagent 返回 concise results:
-
对 large data 使用 filesystem:
Wrong subagent being selected
Problem:Main agent 为 task 调用了不合适的 subagent。 Solution:在 descriptions 中清晰区分 subagents:Connect these docs to Claude, VSCode, and more via MCP for real-time answers.