

概览
LLM 支持的强大应用之一是复杂的问答(Q&A)聊天机器人。这类应用可以回答有关特定源信息的问题。它们使用一种称为检索增强生成的技术,即 RAG。 本教程展示如何基于非结构化文本数据源构建一个简单的 Q&A 应用。本文会演示:概念
本文会介绍以下概念:- 索引:从数据源摄取数据并建立索引的管道。这通常发生在单独的进程中。
- 检索与生成:实际的 RAG 流程,在运行时接收用户查询,从索引中检索相关数据,然后将其传给模型。
预览
在本指南中,本文会构建一个回答网站内容相关问题的应用。这里使用的网站是 Lilian Weng 的博客文章 LLM Powered Autonomous Agents,这样就可以围绕这篇文章的内容提问。 可以用大约 40 行代码创建一个简单的索引管道和 RAG chain。完整代码片段如下:展开完整代码片段
展开完整代码片段
设置
安装
本教程需要以下 langchain 依赖项:LangSmith
使用 LangChain 构建的许多应用会包含多个步骤,并多次调用 LLM。随着这些应用变得更复杂,能够检查 chain 或 agent 内部到底发生了什么会非常关键。实现这一点的最佳方式是使用 LangSmith。 在上面的链接注册后,请设置环境变量以开始记录 trace:组件
需要从 LangChain 的集成套件中选择三个组件。 选择聊天模型:- OpenAI
- Anthropic
- Azure
- Google Gemini
- Bedrock Converse
- OpenAI
- Azure
- AWS
- VertexAI
- MistralAI
- Cohere
- Memory
- MongoDB
- Pinecone
- Qdrant
- Redis
1. 索引
本节是语义搜索教程内容的简略版本。如果你的数据已经建立索引并可供搜索(也就是说,你已经有一个执行搜索的函数),或者你已经熟悉 embeddings 和向量存储,可以直接跳到下一节检索与生成。
- 加载:首先需要将数据加载为
Document对象。 - 拆分:文本拆分器会把大型
Documents拆成更小的块。这对索引数据和传入模型都很有用,因为大块内容更难搜索,也无法放入模型有限的上下文窗口。 - 存储:需要一个位置来存储并索引拆分结果,以便后续搜索。这通常使用 VectorStore 和 Embeddings 模型完成。
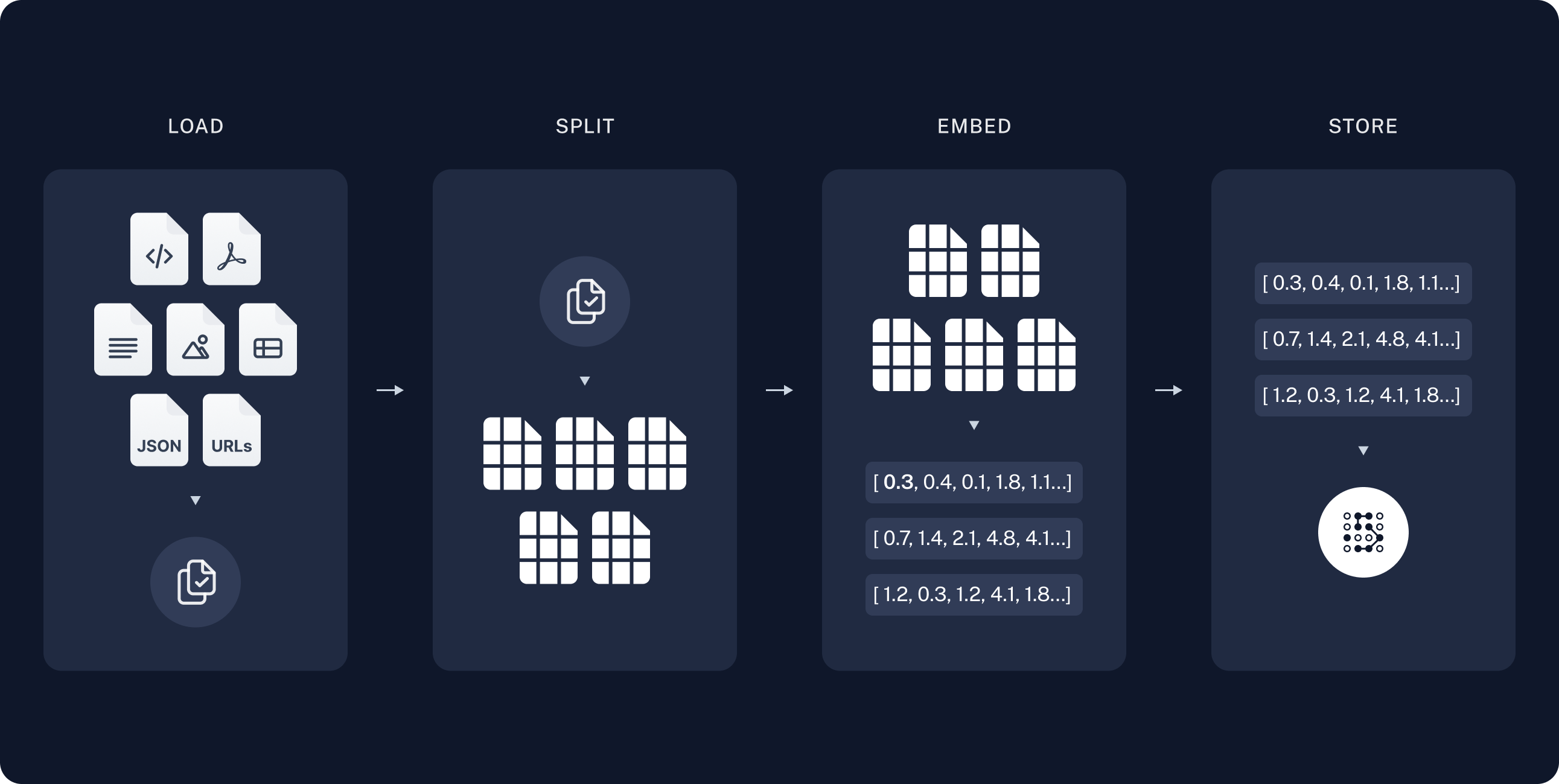
加载文档
首先需要将博客文章内容加载为 Document 对象列表。拆分文档
加载后的文档超过 42k 个字符,对许多模型的上下文窗口来说太长。即使某些模型可以把整篇文章放入上下文窗口,模型也可能很难在非常长的输入中找到信息。 为了解决这个问题,需要将Document 拆分为块,用于 embedding 和向量存储。这可以帮助应用在运行时只检索博客文章中最相关的部分。
与语义搜索教程一样,这里使用 RecursiveCharacterTextSplitter,它会使用换行等常见分隔符递归拆分文档,直到每个块达到合适大小。这是通用文本场景推荐的文本拆分器。
存储文档
现在需要为 66 个文本块建立索引,以便在运行时搜索。按照语义搜索教程的方式,这里的做法是对每个文档拆分结果的内容进行 embed,并将这些 embeddings 插入向量存储。给定输入查询后,就可以使用向量搜索检索相关文档。 可以使用在教程开头选择的向量存储和 embeddings 模型,用一条命令 embed 并存储所有文档拆分结果。Embeddings:文本 embedding 模型的包装器,用于将文本转换为 embeddings。
VectorStore:向量数据库的包装器,用于存储和查询 embeddings。
至此,管道的索引部分完成。此时已经有了一个可查询的向量存储,其中包含博客文章的分块内容。给定用户问题后,理想情况下应该能够返回能回答该问题的博客文章片段。
2. 检索与生成
RAG 应用通常按如下方式工作: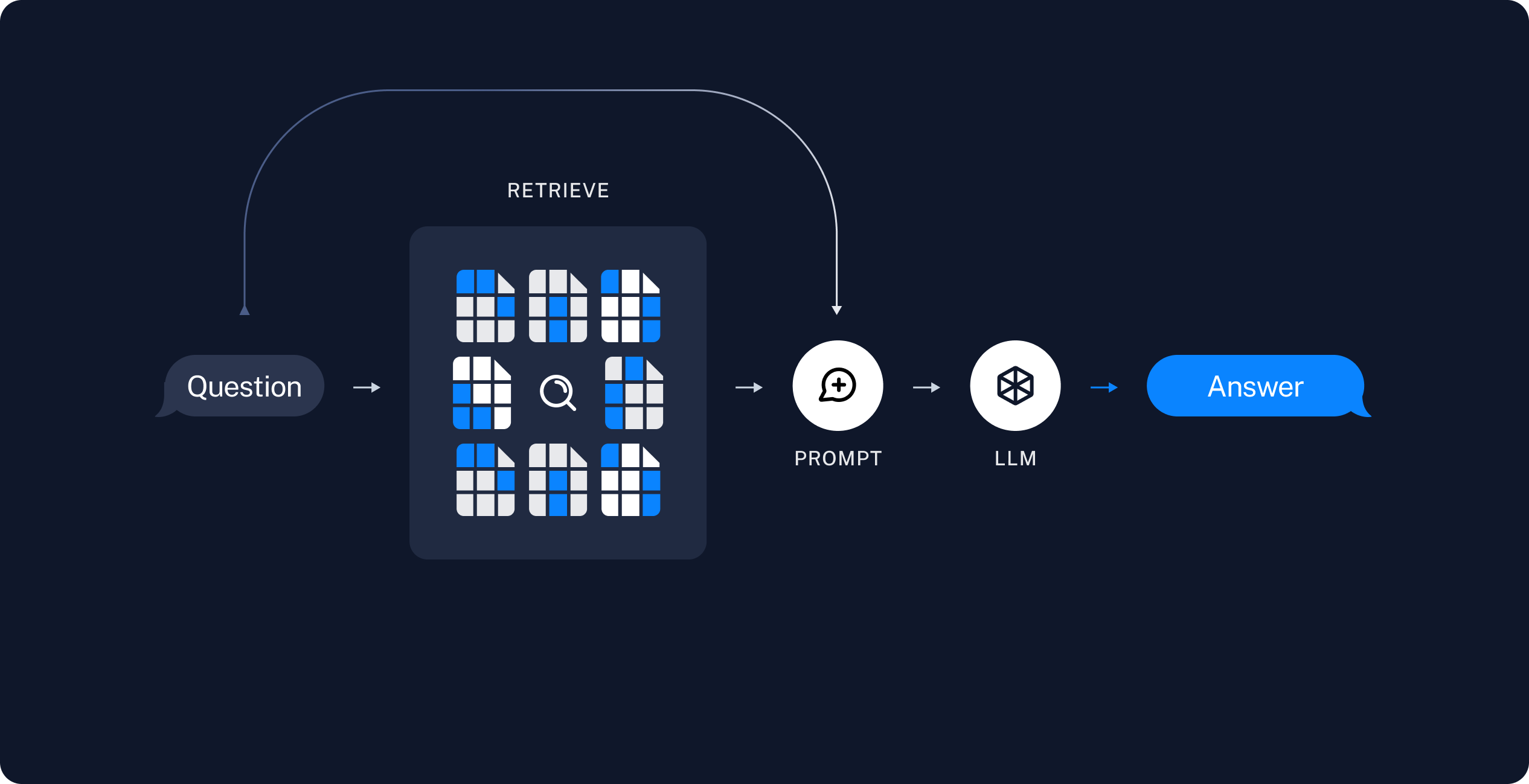 现在编写真正的应用逻辑。目标是创建一个简单应用:接收用户问题,搜索与该问题相关的文档,将检索到的文档和初始问题传给模型,并返回答案。
本文会演示:
现在编写真正的应用逻辑。目标是创建一个简单应用:接收用户问题,搜索与该问题相关的文档,将检索到的文档和初始问题传给模型,并返回答案。
本文会演示:
RAG agents
RAG 应用的一种形式是一个简单 agent,它带有一个检索信息的工具。可以通过实现一个包装向量存储的 tool 来组装一个最小 RAG agent:- 生成一个查询来搜索 task decomposition 的标准方法;
- 收到答案后,生成第二个查询来搜索该方法的常见扩展;
- 收到所有必要上下文后,回答问题。
RAG chains
在上面的 agentic RAG 形式中,LLM 可以自行决定是否生成 tool call 来帮助回答用户查询。这是一个通用性较好的解决方案,但也有一些取舍:| ✅ 优点 | ⚠️ 缺点 |
|---|---|
| 仅在需要时搜索:LLM 可以处理问候、追问和简单查询,而不会触发不必要的搜索。 | 两次推理调用:执行搜索时,需要一次调用生成查询,再用另一次调用生成最终响应。 |
上下文感知搜索查询:将搜索视为带有 query 输入的工具后,LLM 会构造自己的查询,并纳入对话上下文。 | 控制力降低:LLM 可能在实际需要搜索时跳过搜索,或在不必要时发起额外搜索。 |
| 允许多次搜索:LLM 可以执行多次搜索来支持单个用户查询。 |
返回源文档
返回源文档
上面的 RAG chain 会把检索到的上下文纳入该次运行的单个 system message 中。与 agentic RAG 形式一样,有时需要在应用状态中包含原始源文档,以便访问文档元数据。对于两步式 chain,可以通过以下方式实现:
- 向状态添加一个 key,用于存储检索到的文档。
- 通过 middleware hook(例如
before_model)添加新节点,以填充该 key,并注入上下文。
安全性:间接 prompt injection
缓解方式:- 使用防御性 prompt:明确指示模型仅将检索到的上下文视为数据,并忽略其中的任何指令。本教程中的 prompt 包含此类指令。
- 用分隔符包裹上下文:使用清晰的结构标记(例如 XML 标签
<context>...</context>)将检索数据与指令分开,让模型更容易区分两者。 - 验证响应:检查模型输出是否符合预期格式(例如纯文本),并妥善处理意外格式。
后续步骤
现在已经通过createAgent 实现了一个简单的 RAG 应用,可以继续轻松加入新功能并深入探索:
- 流式传输 token 和其他信息,以提供响应式用户体验
- 添加对话记忆,支持多轮交互
- 添加长期记忆,支持跨对话线程的记忆
- 添加结构化响应
- 使用 LangSmith Deployment 部署应用
Connect these docs to Claude, VSCode, and more via MCP for real-time answers.