

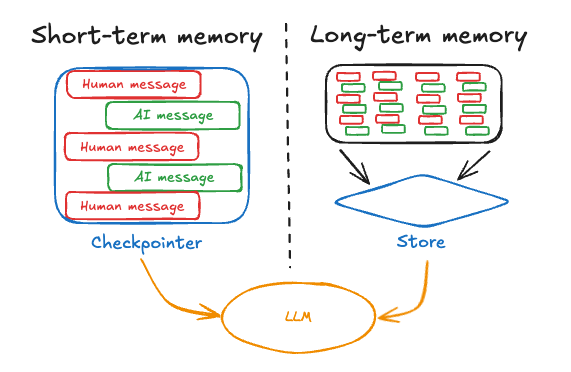
- 短期 memory,也称为限定在 thread 范围内的 memory,它通过维护会话内的消息历史来跟踪正在进行的对话。LangGraph 将短期 memory 作为 agent state 的一部分进行管理。State 会通过 checkpointer 持久化到数据库,因此 thread 可以在任何时候恢复。短期 memory 会在图被调用或某个步骤完成时更新,并且每个步骤开始时都会读取 State。
- 长期 memory 会跨会话存储用户特定数据或应用级数据,并在多个对话 thread 之间 共享。它可以在_任何时候_、任何 thread 中被召回。Memory 的作用域是任意自定义 namespace,而不只是单个 thread ID。LangGraph 提供 store(参考文档),让你保存和召回长期 memory。
短期 memory
短期 memory 让应用能够记住单个 thread 或对话中的先前交互。Thread 会组织一个会话中的多次交互,类似于电子邮件把多条消息归入同一段对话的方式。 LangGraph 将短期 memory 作为 agent state 的一部分进行管理,并通过限定在 thread 范围内的 checkpoint 持久化。该 state 通常可以包含对话历史以及其他有状态数据,例如上传的文件、检索到的文档或生成的 artifact。通过把这些内容存储在图的 state 中,bot 可以访问指定对话的完整上下文,同时保持不同 thread 之间的隔离。管理短期 memory
对话历史是最常见的短期 memory 形式,而长对话会给当今的 LLM 带来挑战。完整历史可能无法放入 LLM 的上下文窗口,从而导致不可恢复的错误。即使你的 LLM 支持完整上下文长度,大多数 LLM 在长上下文上的表现仍然较差。它们会被过时或偏离主题的内容“分散注意力”,同时响应更慢、成本更高。 聊天模型通过消息接收上下文,消息包括开发者提供的指令(system message)和用户输入(human message)。在聊天应用中,消息会在人类输入和模型响应之间交替出现,形成一个随时间不断增长的消息列表。由于上下文窗口有限,而且包含大量 token 的消息列表成本很高,许多应用都可以受益于手动移除或遗忘过时信息的技术。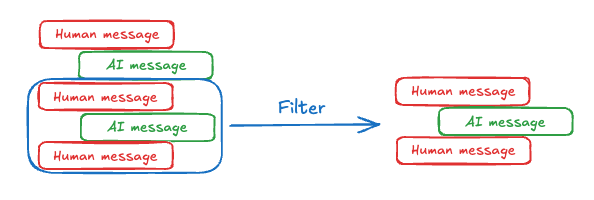 有关管理消息的常见技术,请参阅添加和管理 memory 指南。
有关管理消息的常见技术,请参阅添加和管理 memory 指南。
长期 memory
LangGraph 中的长期 memory 允许系统跨不同对话或会话保留信息。短期 memory 的作用域限定在 thread 内,而长期 memory 会保存在自定义 “namespace” 中。 长期 memory 是一个复杂挑战,没有适用于所有场景的单一方案。不过,下列问题可以作为框架,帮助你理解不同技术:- Memory 的类型是什么?人类会用 memory 记住事实(语义 memory)、经历(情景 memory)和规则(程序性 memory)。AI agent 也可以以相同方式使用 memory。例如,AI agent 可以使用 memory 来记住关于用户的特定事实,以完成任务。
- 你希望何时更新 memory? Memory 可以作为 agent 应用逻辑的一部分更新,例如在 “hot path” 中。在这种情况下,agent 通常会在响应用户之前决定要记住哪些事实。另一种方式是把 memory 更新作为后台任务执行,即在后台异步运行并生成 memory 的逻辑。下方的相关章节说明了这些方法之间的权衡。
语义 memory
语义 memory 在人类和 AI agent 中都涉及对特定事实和概念的保留。对人类而言,它可以包括在学校学到的信息,以及对概念及其关系的理解。对 AI agent 而言,语义 memory 常用于通过记住过去交互中的事实或概念来个性化应用。语义 memory 不同于 “semantic search”。Semantic search 是一种使用“含义”(通常表现为 embedding)查找相似内容的技术。语义 memory 是一个心理学术语,指事实和知识的存储;semantic search 则是一种根据含义而非精确匹配来检索信息的方法。
Profile
Memory 可以是单个持续更新的 “profile”,其中包含关于用户、组织或其他实体(包括 agent 自身)的范围明确且具体的信息。Profile 通常只是一个 JSON 文档,包含你为领域选择的一组 key-value pair。 记住 profile 时,你需要确保每次都在更新该 profile。因此,你需要传入之前的 profile,并要求模型生成新的 profile,或生成某种可应用到旧 profile 的 JSON patch。随着 profile 变大,这可能更容易出错,因此可以考虑把一个 profile 拆分为多个文档,或在生成文档时使用严格解码,以确保 memory schema 保持有效。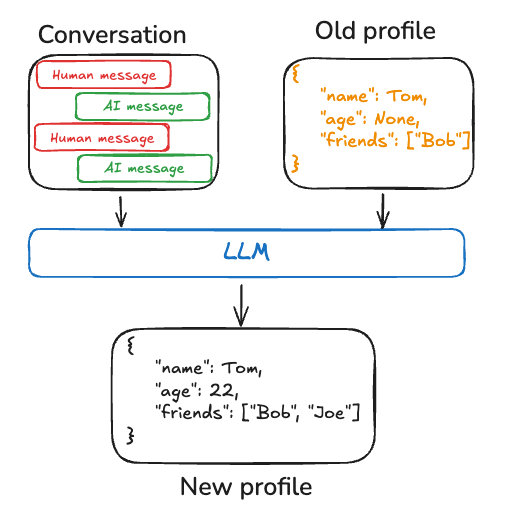
Collection
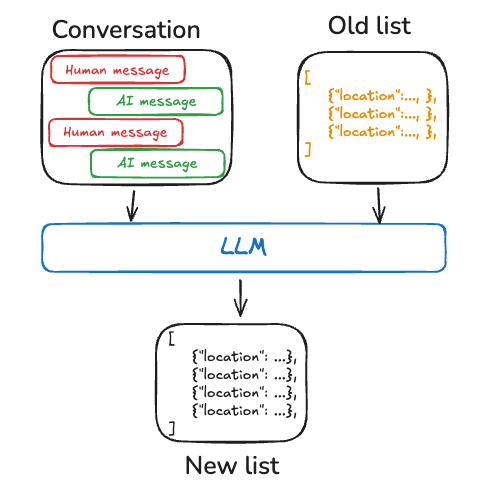
另一种方式是把 memory 表示为一组会随时间持续更新和扩展的文档。每条单独的 memory 可以有更窄的作用域,也更容易生成,这意味着你随时间丢失信息的可能性更低。对 LLM 来说,为新信息生成_新_对象,通常比把新信息协调进现有 profile 更容易。因此,文档集合往往会在下游带来更高的召回率。 不过,这会把一部分复杂性转移到 memory 更新上。模型现在必须_删除_或_更新_列表中的现有项,这可能很棘手。此外,一些模型可能默认过度插入,另一些模型可能默认过度更新。可以参阅 Trustcall 包了解一种管理方式,并考虑使用评估,例如借助 LangSmith,来帮助你调优行为。 使用文档集合还会把复杂性转移到针对列表的 memory 搜索上。Store 目前同时支持 semantic search 和按内容过滤。
最后,使用 memory 集合可能让向模型提供完整上下文变得更困难。虽然单条 memory 可以遵循特定 schema,但这种结构可能无法捕获 memory 之间的完整上下文或关系。因此,在使用这些 memory 生成响应时,模型可能缺少重要上下文,而这些上下文在统一 profile 方法中更容易获得。
 无论使用哪种 memory 管理方法,核心点都是 agent 会使用语义 memory 来支撑其响应,这通常会带来更个性化、更相关的交互。
无论使用哪种 memory 管理方法,核心点都是 agent 会使用语义 memory 来支撑其响应,这通常会带来更个性化、更相关的交互。
情景 memory
情景 memory 在人类和 AI agent 中都涉及对过去事件或动作的回忆。CoALA paper 对这一点表述得很好:事实可以写入语义 memory,而经历可以写入情景 memory。对 AI agent 而言,情景 memory 常用于帮助 agent 记住如何完成任务。 在实践中,情景 memory 通常通过 few-shot 示例 prompting 实现,agent 从过去的序列中学习如何正确执行任务。有时“展示”比“说明”更容易,LLM 也能很好地从示例中学习。Few-shot learning 让你通过使用 input-output 示例更新 prompt 来“编程”你的 LLM,从而说明预期行为。虽然可以使用各种最佳实践来生成 few-shot 示例,但挑战通常在于根据用户输入选择最相关的示例。 请注意,memory store 只是把数据存储为 few-shot 示例的一种方式。如果你希望开发者更多参与,或希望 few-shot 更紧密地绑定到评估 harness,也可以使用 LangSmith Dataset 存储数据,并实现自己的检索逻辑,根据用户输入选择最相关的示例。 请参阅这篇展示如何使用 few-shot prompting 提升工具调用性能的博客文章,以及这篇使用 few-shot 示例让 LLM 与人类偏好对齐的博客文章。程序性 memory
程序性 memory 在人类和 AI agent 中都涉及对执行任务所用规则的记忆。对人类而言,程序性 memory 类似于如何执行任务的内化知识,例如通过基本运动技能和平衡来骑自行车。另一方面,情景 memory 涉及回忆具体经历,例如第一次不用辅助轮成功骑车,或一次难忘的风景骑行。对 AI agent 而言,程序性 memory 是模型权重、agent 代码和 agent prompt 的组合,它们共同决定 agent 的功能。 在实践中,agent 修改自己的模型权重或重写自身代码并不常见。不过,agent 修改自身 prompt 更常见。 改进 agent 指令的一种有效方法是使用 “Reflection” 或 meta-prompting。这涉及把 agent 当前指令,例如 system prompt,与最近对话或明确的用户反馈一起提供给 agent。随后 agent 会基于该输入改进自身指令。对于难以预先指定指令的任务,这种方法尤其有用,因为它允许 agent 从交互中学习和适应。 例如,LangChain 使用外部反馈和 prompt 重写构建了一个 Tweet generator,用于为 Twitter 生成高质量论文摘要。在这个案例中,具体的摘要 prompt 很难a priori指定,但用户可以相对容易地评价生成的 Tweet,并提供如何改进摘要流程的反馈。 下面的伪代码展示了如何结合 LangGraph memory store 实现这一点:使用 store 保存 prompt,使用update_instructions 节点获取当前 prompt,以及从 state["messages"] 捕获的用户对话反馈,更新 prompt,并把新的 prompt 保存回 store。随后,call_model 从 store 获取更新后的 prompt,并用它生成响应。
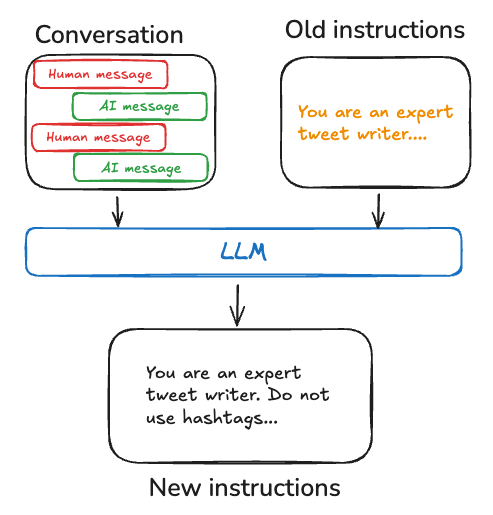
写入 memory
Agent 写入 memory 主要有两种方法:“在 hot path 中”和“在后台”。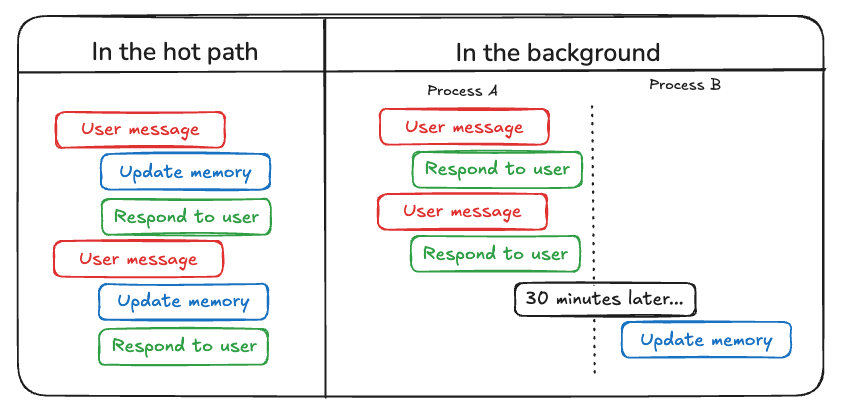
在 hot path 中
在运行时创建 memory 既有优势也有挑战。积极的一面是,这种方法支持实时更新,让新 memory 可以立即用于后续交互。它还支持透明度,因为可以在创建并存储 memory 时通知用户。 不过,这种方法也带来挑战。如果 agent 需要一个新工具来决定要把什么提交到 memory,复杂性可能会增加。此外,推理要保存什么内容可能影响 agent 延迟。最后,agent 必须在创建 memory 和承担其他职责之间多任务处理,这可能影响创建出的 memory 数量和质量。 例如,ChatGPT 使用 save_memories 工具将 memory 作为内容字符串 upsert,并在每条用户消息中决定是否以及如何使用该工具。请参阅 memory-agent 模板作为参考实现。在后台
将创建 memory 作为独立后台任务有几个优势。它消除了主应用中的延迟,将应用逻辑与 memory 管理分离,并让 agent 更专注地完成任务。这种方法还可以灵活安排 memory 创建时机,从而避免重复工作。 不过,这种方法也有自己的挑战。确定 memory 写入频率变得很关键,因为更新过少可能会让其他 thread 缺少新上下文。决定何时触发 memory 形成也很重要。常见策略包括在设定时间段后调度,如果发生新事件则重新调度,使用 cron schedule,或允许用户或应用逻辑手动触发。 请参阅 memory-service 模板作为参考实现。Memory 存储
LangGraph 会将长期 memory 作为 JSON 文档存储在 store 中。每条 memory 都组织在一个自定义namespace(类似文件夹)和一个不同的 key(类似文件名)之下。Namespace 通常包含用户 ID、组织 ID 或其他标签,便于组织信息。这种结构支持 memory 的层级组织。随后可通过内容过滤器支持跨 namespace 搜索。
延伸阅读
Connect these docs to Claude, VSCode, and more via MCP for real-time answers.