多代理系统会协调专门化组件来处理复杂工作流。不过,并非每个复杂任务都需要这种方法。一个具备合适工具(有时是动态工具)和提示词的单代理,通常也能取得类似结果。
为什么使用多代理?
当开发者说需要“多代理”时,通常是在寻找以下一种或多种能力:
- 上下文管理:提供专门知识,同时不压垮模型的上下文窗口。如果上下文无限且延迟为零,你可以把所有知识都放进一个提示词;但现实并非如此,因此需要用模式来选择性地呈现相关信息。
- 分布式开发:让不同团队独立开发和维护能力,并以清晰边界组合成更大的系统。
- 并行化:为子任务生成专门工作单元,并并发执行以更快获得结果。
当单个代理拥有过多工具且难以正确决定使用哪一个,任务需要带大量上下文的专门知识(长提示词和领域专用工具),或者你需要强制顺序约束,只有满足特定条件后才解锁能力时,多代理模式尤其有价值。
以下是构建多代理系统的主要模式,每种模式都适用于不同用例:
| 模式 | 工作方式 |
|---|
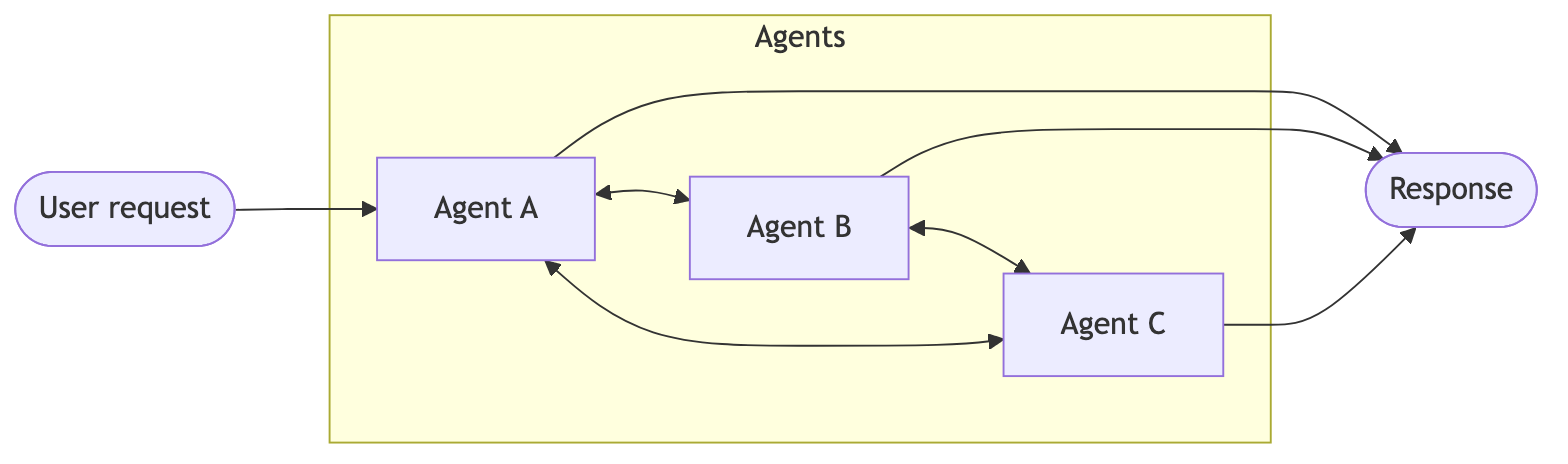
| Subagents | 主代理将子代理作为工具进行协调。所有路由都经过主代理,由主代理决定何时以及如何调用每个子代理。 |
| Handoffs | 行为会根据状态动态变化。工具调用会更新状态变量,从而触发路由或配置变化,切换代理,或调整当前代理的工具和提示词。 |
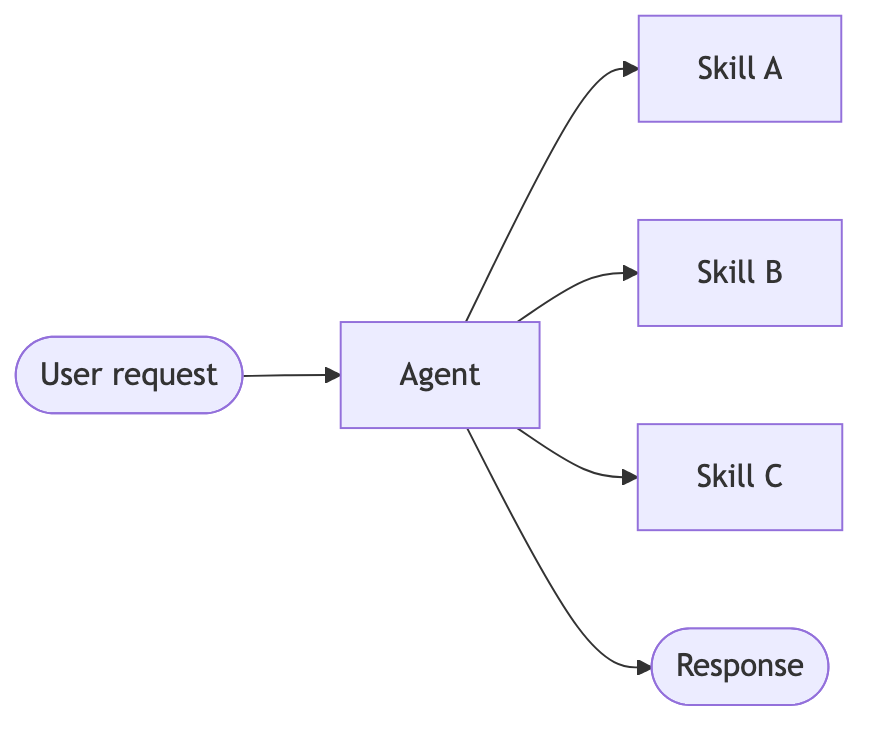
| Skills | 按需加载专门提示词和知识。单个代理保持控制权,并根据需要从技能中加载上下文。 |
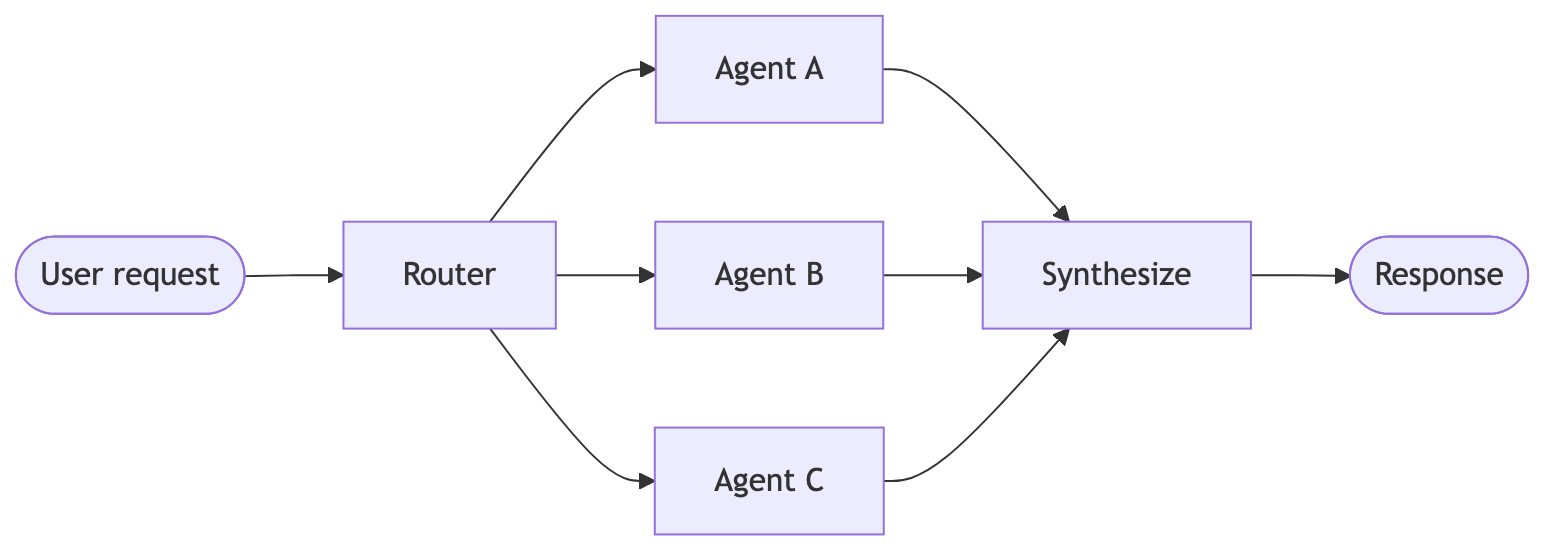
| Router | 路由步骤对输入分类,并将其定向到一个或多个专门代理。结果会被综合成合并响应。 |
| Custom workflow | 使用 LangGraph 构建定制执行流程,混合确定性逻辑和代理式行为。将其他模式作为节点嵌入工作流。 |
选择模式
使用下表将需求匹配到合适模式:
- 分布式开发:不同团队是否可以独立维护组件?
- 并行化:多个代理是否可以并发执行?
- 多跳:该模式是否支持串行调用多个子代理?
- 直接用户交互:子代理是否可以直接与用户对话?
你可以混合使用多种模式。例如,subagents 架构可以调用会触发自定义工作流或 router 代理的工具。子代理甚至可以使用 skills 模式按需加载上下文。组合方式非常灵活。
可视化概览
Subagents
Handoffs
Skills
Router
主代理将子代理作为工具进行协调。所有路由都经过主代理。 代理通过工具调用相互转移控制权。每个代理都可以移交给其他代理,或直接响应用户。 路由步骤对输入分类,并将其定向到专门代理。随后综合结果。 性能对比
不同模式具有不同性能特征。了解这些权衡有助于根据延迟和成本需求选择合适模式。
关键指标:
- 模型调用:LLM 调用次数。调用越多,延迟越高(尤其是串行调用时),每次请求的 API 成本也越高。
- 处理的 token:所有调用中的总上下文窗口使用量。token 越多,处理成本越高,也越可能触及上下文限制。
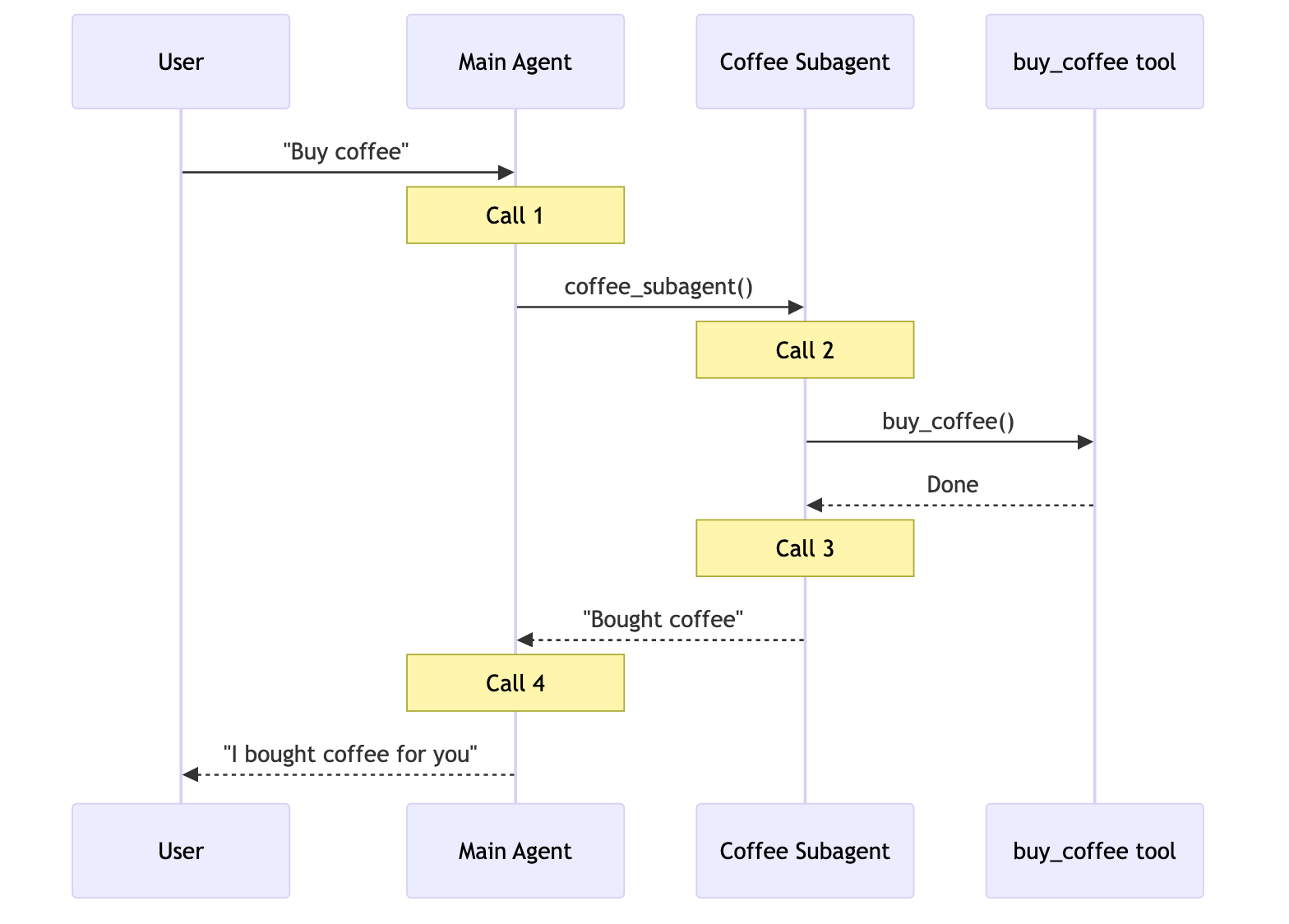
一次性请求
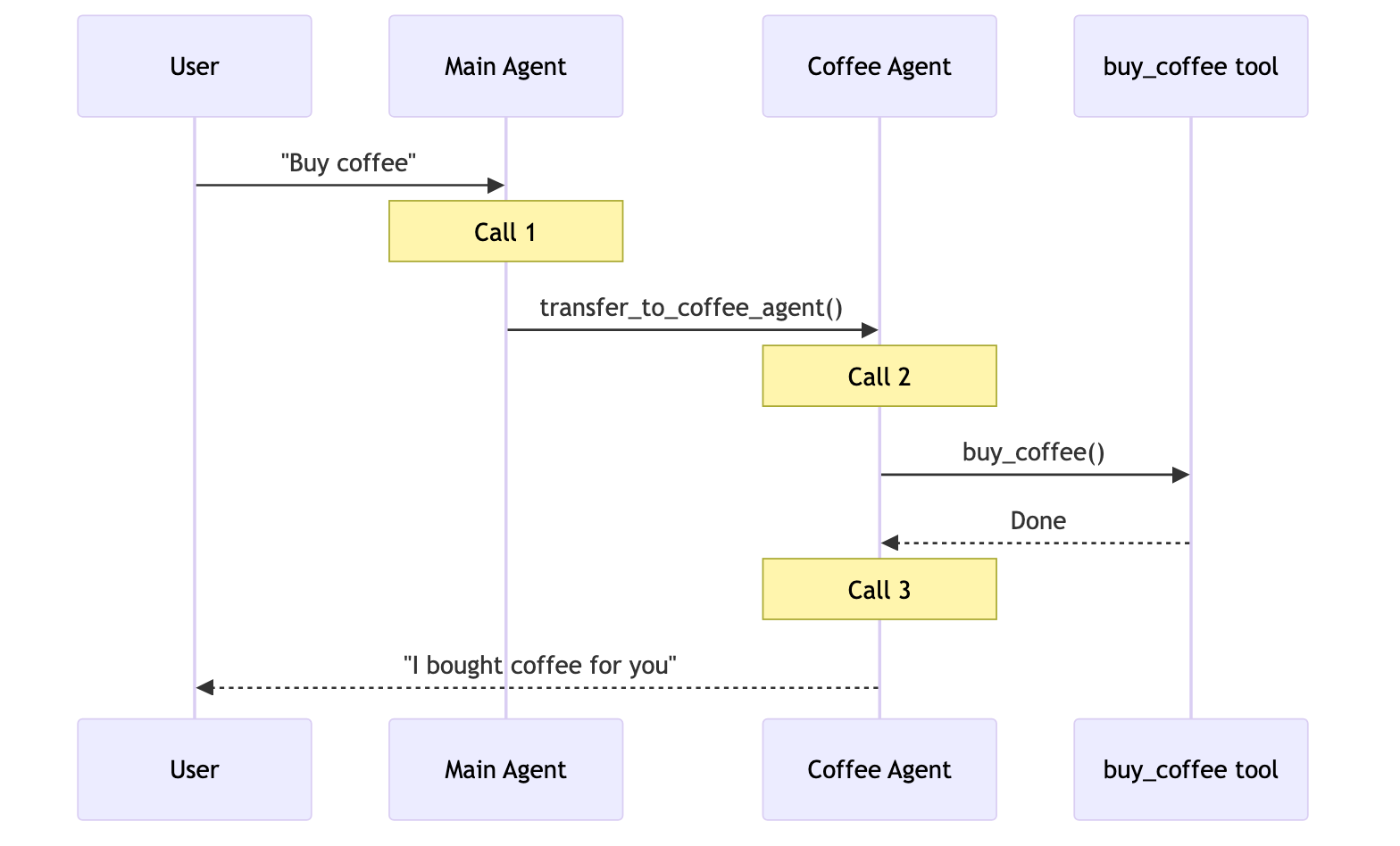
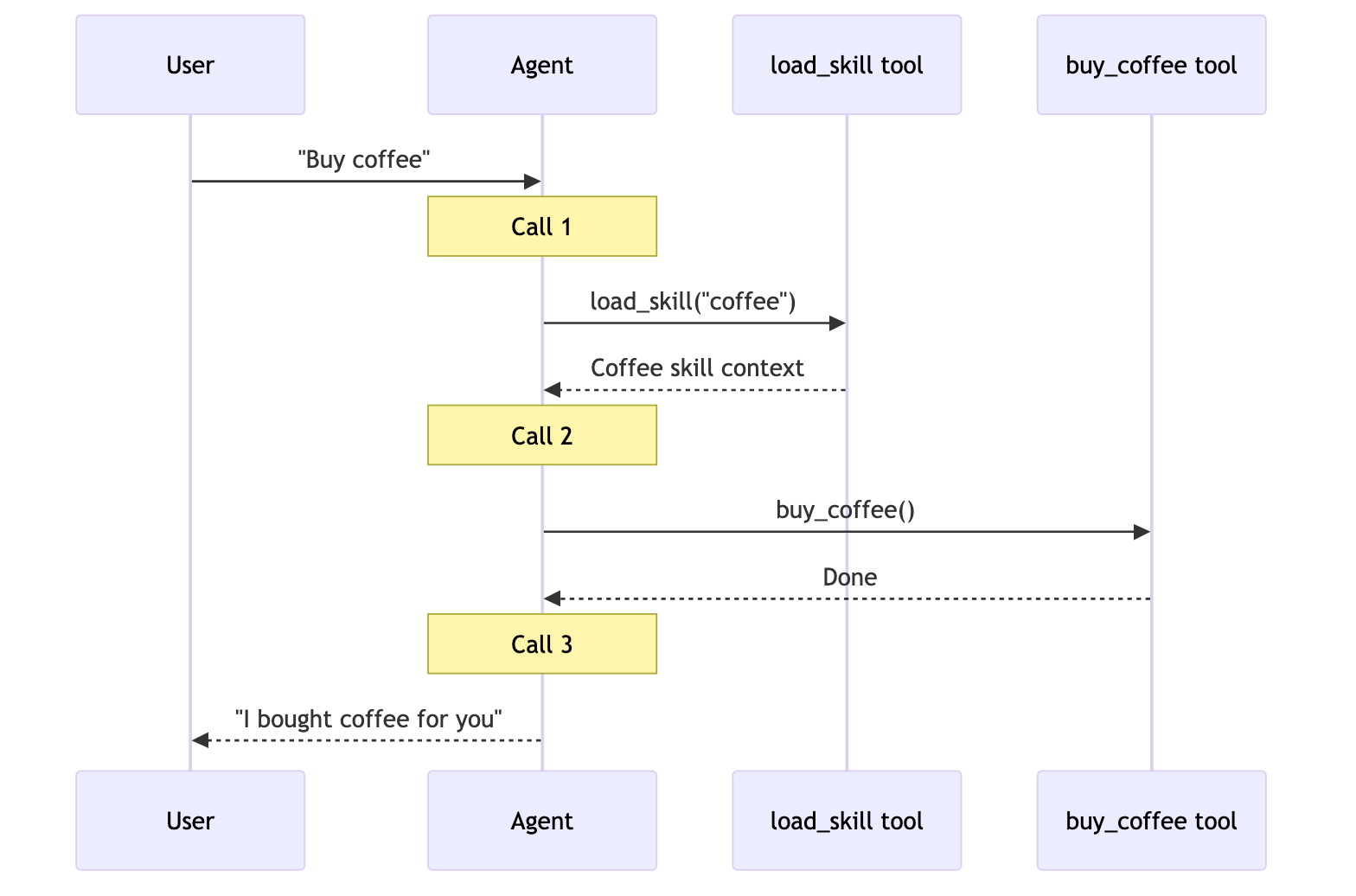
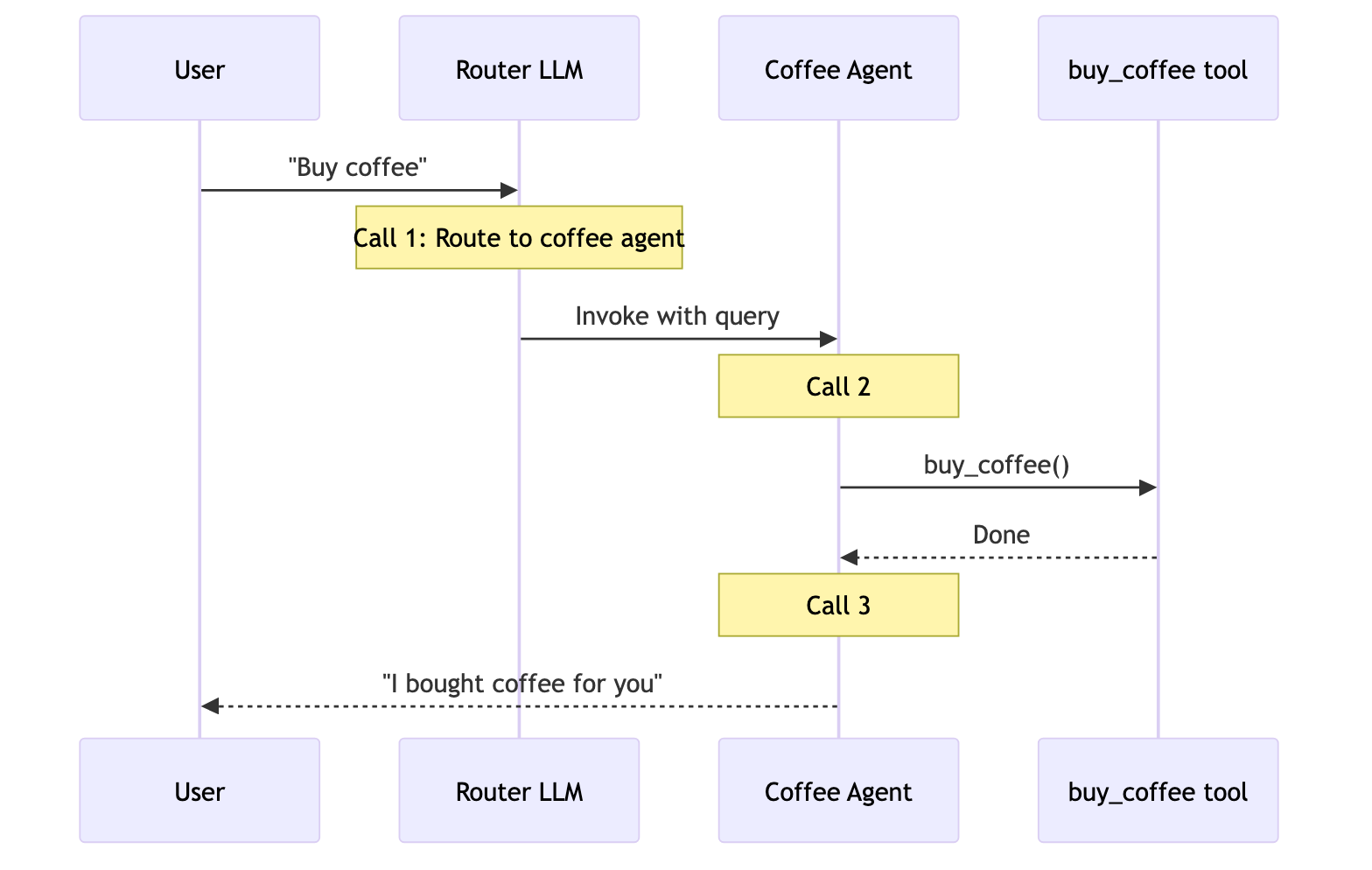
用户: “Buy coffee”
专门的咖啡代理或技能可以调用 buy_coffee 工具。
Subagents
Handoffs
Skills
Router
重复请求
第 1 轮: “Buy coffee”
第 2 轮: “Buy coffee again”
用户在同一对话中重复相同请求。
Subagents
Handoffs
Skills
Router
再次 4 次调用 → 总计 8 次
- Subagents 设计上是无状态的,每次调用都遵循相同流程
- 主代理维护对话上下文,但子代理每次都会从全新状态开始
- 这提供了强上下文隔离,但会重复完整流程
2 次调用 → 总计 5 次
- 咖啡代理从第 1 轮起仍处于活动状态(状态持久存在)
- 不需要 handoff,代理直接调用
buy_coffee 工具(调用 1)
- 代理响应用户(调用 2)
- 跳过 handoff,节省 1 次调用
2 次调用 → 总计 5 次
- 技能上下文已在对话历史中加载
- 不需要重新加载,代理直接调用
buy_coffee 工具(调用 1)
- 代理响应用户(调用 2)
- 复用已加载技能,节省 1 次调用
再次 3 次调用 → 总计 6 次
- Router 是无状态的,每次请求都需要一次 LLM 路由调用
- 第 2 轮:Router LLM 调用(1)→ Milk agent 调用 buy_coffee(2)→ Milk agent 响应(3)
- 可以通过将其封装为有状态代理中的工具来优化
多领域
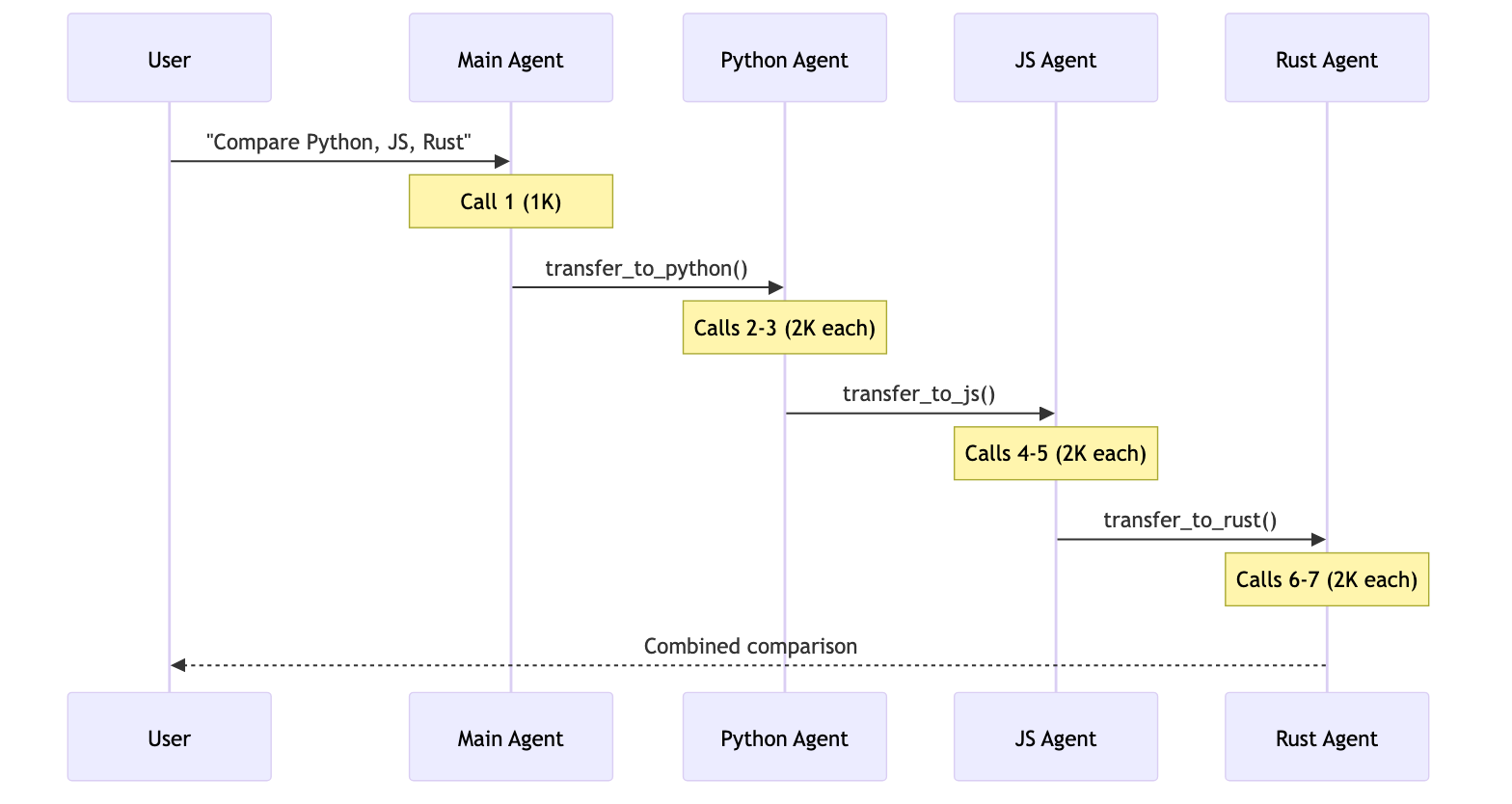
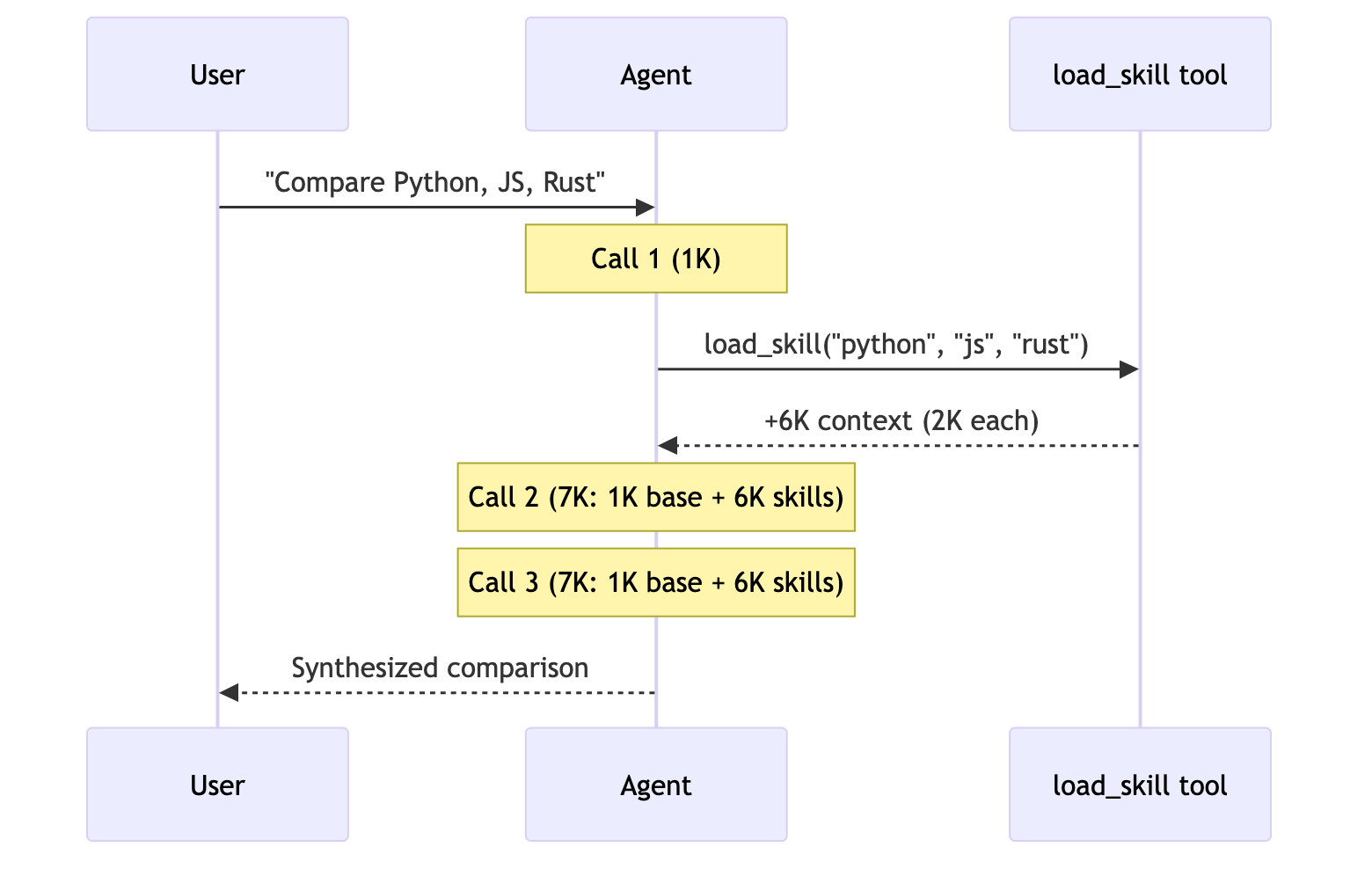
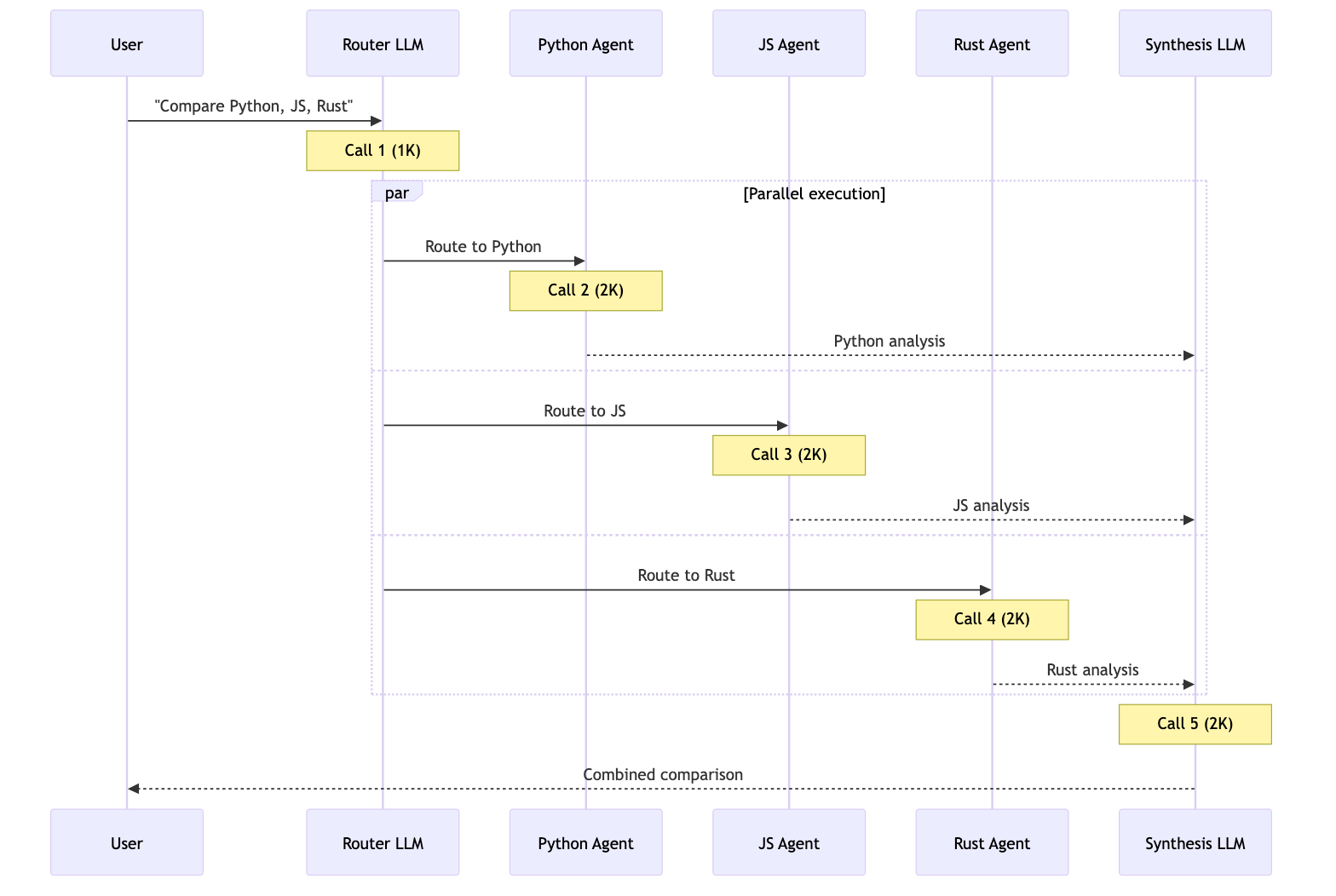
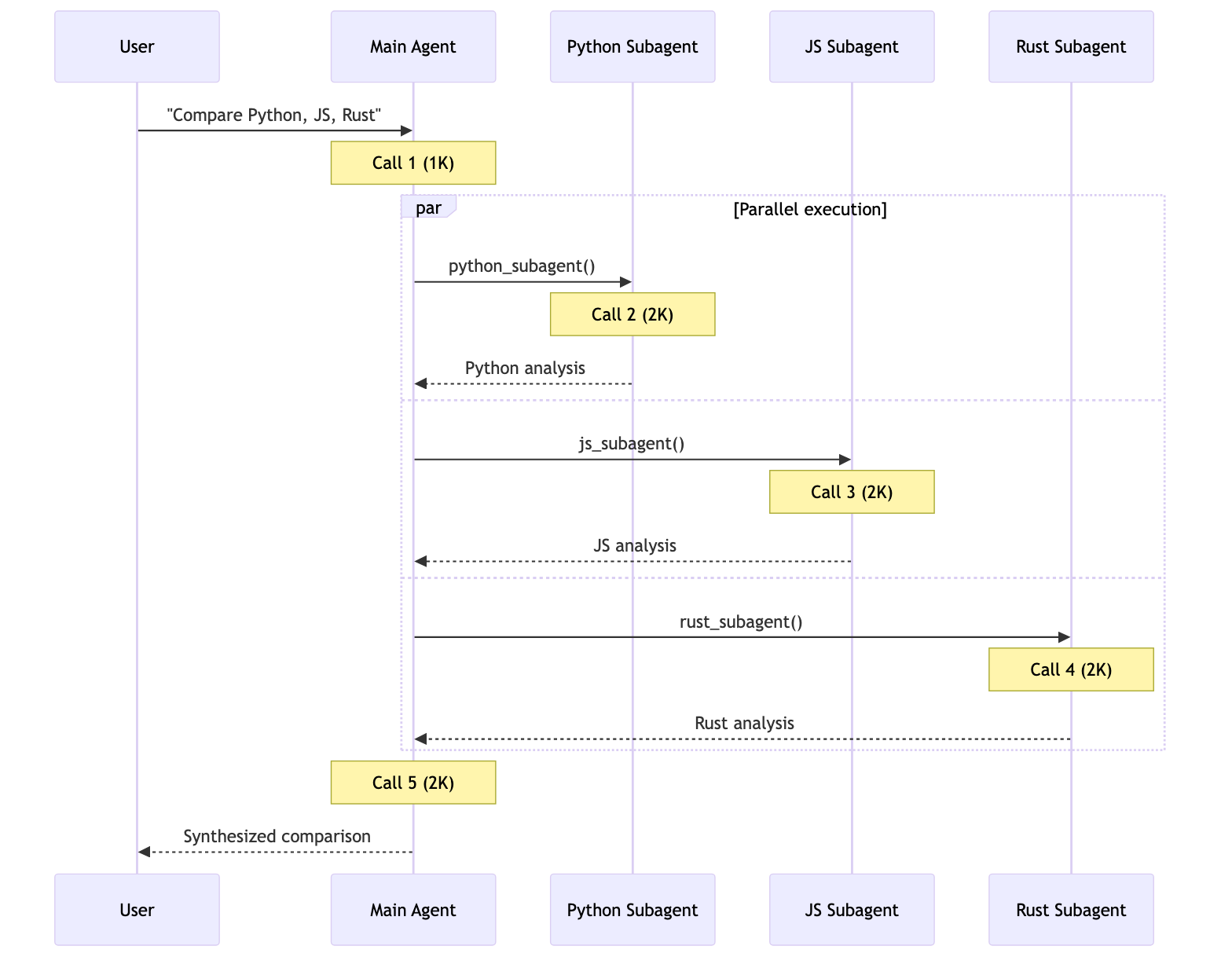
用户: “Compare Python, JavaScript, and Rust for web development”
每个语言代理或技能都包含约 2000 个 token 的文档。所有模式都可以进行并行工具调用。
| 模式 | 模型调用 | token 总数 | 最适合 |
|---|
| Subagents | 5 | ~9K | ✅ |
| Handoffs | 7+ | ~14K+ | |
| Skills | 3 | ~15K | |
| Router | 5 | ~9K | ✅ |
Subagents
Handoffs
Skills
Router
5 次调用,约 9K token每个子代理只在相关上下文中隔离工作。总计:9K token。 7+ 次调用,约 14K+ tokenHandoffs 会串行执行,无法并行研究三种语言。不断增长的对话历史会增加开销。总计:约 14K+ token。 3 次调用,约 15K token加载后,之后每次调用都会处理全部 6K token 的技能文档。由于上下文隔离,Subagents 总体少处理 67% 的 token。总计:15K token。 5 次调用,约 9K tokenRouter 使用 LLM 进行路由,然后并行调用代理。它类似于 Subagents,但有显式路由步骤。总计:9K token。 | 模式 | 一次性请求 | 重复请求 | 多领域 |
|---|
| Subagents | 4 次调用 | 8 次调用(4+4) | 5 次调用,9K token |
| Handoffs | 3 次调用 | 5 次调用(3+2) | 7+ 次调用,14K+ token |
| Skills | 3 次调用 | 5 次调用(3+2) | 3 次调用,15K token |
| Router | 3 次调用 | 6 次调用(3+3) | 5 次调用,9K token |


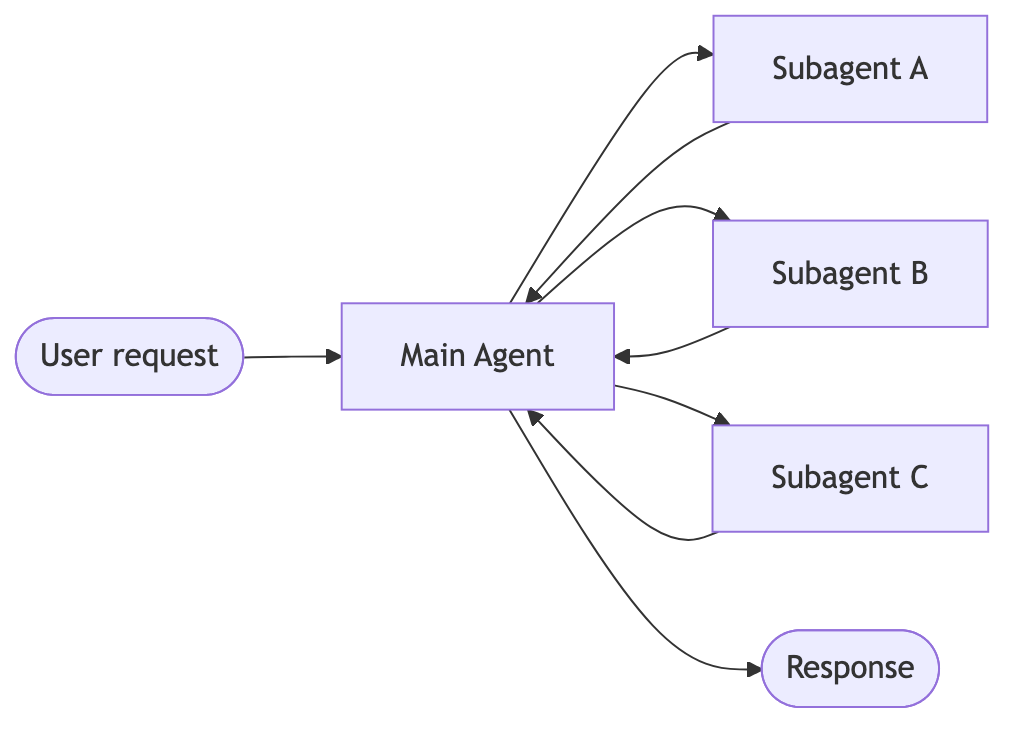
 每个子代理只在相关上下文中隔离工作。总计:9K token。
每个子代理只在相关上下文中隔离工作。总计:9K token。